Le POC qui meurt sur le laptop du data scientist
Il y a un scénario que tous les industriels qui ont financé un projet ML connaissent. Un data scientist externe arrive, récupère trois mois d’historique machine, construit un modèle XGBoost ou LSTM avec une métrique flatteuse en validation croisée, livre un notebook Jupyter, fait une démo en comité de pilotage avec deux courbes bleues qui se superposent, et repart.
Le notebook reste sur un serveur partagé. Personne n’a accès à l’environnement Python qui va avec. Aucun mécanisme ne récupère les nouvelles données pour recalculer les prédictions. Six mois plus tard, le sponsor se fait demander où en est le projet IA, et il ouvre le slide qui dit que le modèle avait atteint 92 % de précision. Fin de l’histoire.
La majorité des projets ML en industrie échouent non pas à la modélisation, mais au déploiement. La modélisation est la partie agréable, celle qu’on enseigne, celle qu’on présente en conférence. Le déploiement est la partie difficile, souvent méprisée, et pourtant c’est celle qui décide si un projet ML est un actif ou un souvenir de POC.
Cet article parle des deux parties, avec un biais assumé pour la deuxième.
CRISP-DM — le cadre qu’on moque et qu’on applique tous
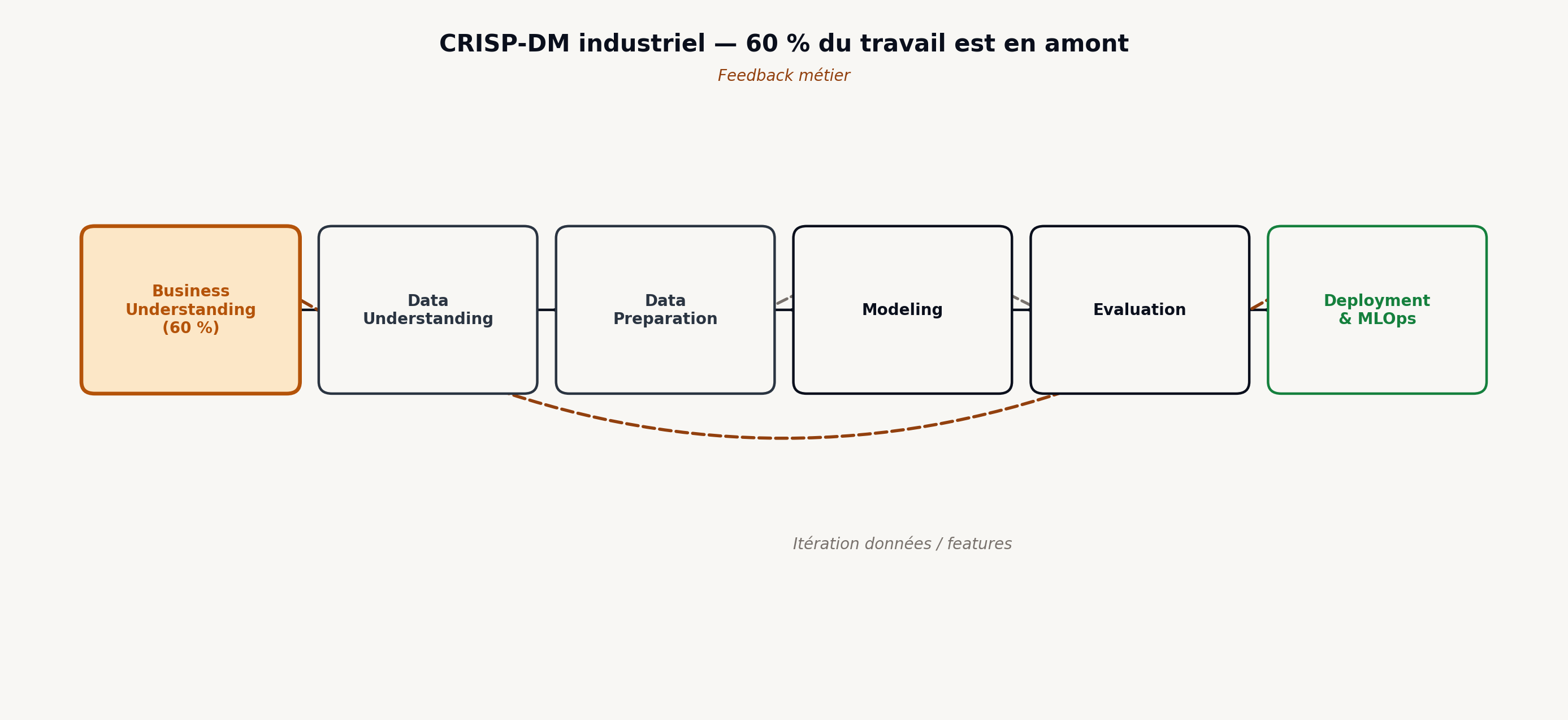
CRISP-DM (Cross-Industry Standard Process for Data Mining) a presque trente ans. On se moque de son âge, on le présente comme “pas agile”, on préfère parler de MLOps ou de data mesh. Et pourtant, quand on regarde les projets ML industriels qui livrent, ils suivent tous, à la lettre ou inconsciemment, les six étapes de CRISP-DM : Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation, Deployment.
La leçon la plus importante de CRISP-DM tient en une phrase : Business Understanding représente environ 60 % de la valeur d’un projet ML, et pourtant c’est l’étape la plus souvent bâclée.
Je ne parle pas du slide “contexte” dans la proposition commerciale. Je parle du travail d’aller sur site, de passer deux journées en atelier avec le chef de production, de comprendre comment les arrêts sont réellement gérés, quel est le coût d’une fausse alarme versus un vrai positif manqué, à qui sera destinée la prédiction, comment elle sera intégrée dans la routine quotidienne.
Sans ce travail, un modèle avec 98 % de précision peut être inutile — soit parce qu’il prédit le mauvais événement, soit parce que la décision qui en découle arrive trop tard pour agir.
Data Understanding — les pièges propres à l’industriel
Les données industrielles ne ressemblent pas aux données web. Elles sont cabossées. Quelques pièges systématiques à connaître avant même d’écrire une ligne de code.
Échantillonnage hétérogène. Les capteurs ne remontent pas tous à la même fréquence. Température toutes les 5 secondes, pression toutes les minutes, vitesse toutes les 100 ms. Combiner ces flux demande un réchantillonnage — par interpolation, agrégation de fenêtres, ou dernière valeur connue. Une interpolation linéaire sur un signal bruité introduit de fausses variations ; une dernière valeur connue sur un signal qui dérive introduit un biais temporel. Pas de règle universelle, des décisions à documenter.
Valeurs manquantes systématiques. Les capteurs sont éteints pendant les périodes de maintenance. Un NaN n’est pas forcément une donnée manquante au sens statistique — c’est souvent l’information “la machine était arrêtée”. Traiter ces NaN par simple imputation (moyenne, médiane) détruit une information précieuse. La bonne pratique est de créer une variable indicatrice machine_off en parallèle du remplissage.
Horodatage pourri. Les horloges des automates dérivent. Les resynchronisations NTP introduisent des sauts de quelques secondes. Les logs issus de deux sources différentes peuvent être désynchronisés de 3 secondes sans que ce soit visible à l’œil. Sur un problème de prédiction de défaut à quelques secondes près, ce décalage tue le modèle. Un contrôle systématique de la cohérence temporelle fait partie de tout audit de données industrielles sérieux.
Drift des instruments. Un capteur de pression dérive à cause de l’encrassement de la membrane. Un modèle entraîné sur 6 mois de données d’un capteur sain ne prédira plus rien après 18 mois si personne n’a recalibré. On en reparle plus bas dans le monitoring post-déploiement.
Data Preparation — feature engineering sur signaux time-series
Un signal brut de capteur n’est presque jamais une bonne variable d’entrée pour un modèle. Le feature engineering — la construction de descripteurs dérivés du signal — est souvent plus déterminant que le choix du modèle lui-même. Quelques techniques qui fonctionnent.
Fenêtres glissantes statistiques. Sur une fenêtre de N secondes, on calcule moyenne, écart-type, min, max, skewness, kurtosis. On fait glisser la fenêtre d’un pas (typiquement 1 seconde ou 1 minute).
On obtient des descripteurs qui capturent le comportement local du signal. C’est simple, c’est robuste, et pour 70 % des problèmes industriels de supervision, ça suffit.
Décomposition STL (Seasonal-Trend decomposition using Loess). Pour un signal qui mélange une tendance, une saisonnalité et du bruit — typiquement la consommation électrique d’une ligne qui tourne en 3-8 — la décomposition STL sépare ces trois composantes, et permet d’entraîner le modèle sur les résidus, beaucoup plus informatifs que le signal brut.
FFT sur vibrations. Pour les signaux vibratoires (paliers, moteurs, pompes), le domaine fréquentiel est souvent plus parlant que le domaine temporel. Une FFT sur une fenêtre de 1024 points, suivie d’une agrégation par bandes de fréquence, donne des descripteurs qui corrèlent avec les modes de défaillance mécanique (balourd, désalignement, défaut roulement). La signature fréquentielle d’un roulement usé est une variable d’entrée bien plus forte que le simple RMS.
Labels par événement. La question “quel label associer à chaque ligne du jeu de données” est souvent mal posée. On a tendance à labelliser par fenêtre temporelle, ce qui crée des déséquilibres massifs (beaucoup de “sain” pour un seul “défaut”). La bonne pratique est de labelliser autour de l’événement : les N secondes avant un déclenchement d’alarme sont labellisées “pré-défaut”, les secondes suivantes “défaut”, le reste “sain”. Cette segmentation ciblée change radicalement la performance.
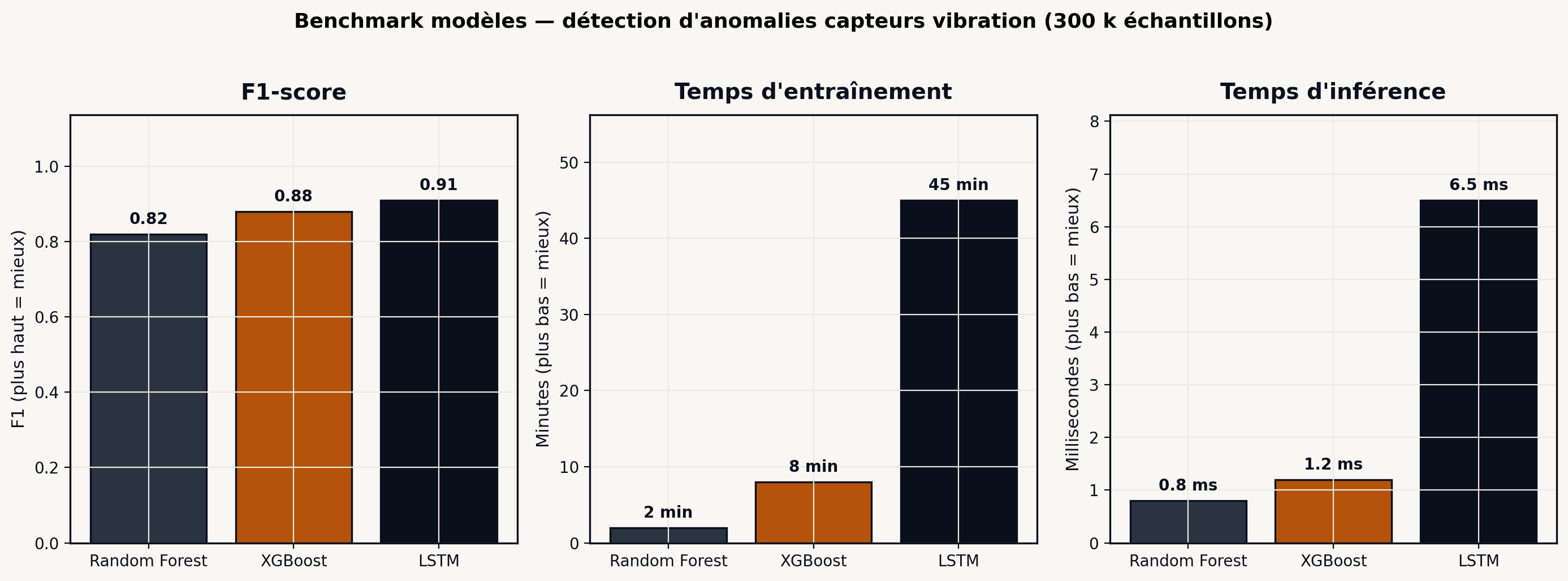
Modeling — quand choisir Random Forest, XGBoost ou LSTM
Le choix du modèle dépend de cinq critères pratiques : volume de données, présence de saisonnalité/dépendance temporelle, besoin d’interprétabilité, contrainte temps réel, et maturité des équipes client. Voici un tableau décisionnel pragmatique.
| Contexte | Modèle recommandé | Pourquoi |
|---|---|---|
| < 10K échantillons, problème tabulaire, interprétabilité exigée | Random Forest | Robuste, peu d’hyperparamètres, feature importance native |
| 10K-10M échantillons, problème tabulaire, précision prioritaire | XGBoost / LightGBM | Meilleure performance sur données tabulaires, supporte grand volume |
| Signaux time-series, dépendance temporelle longue (> 50 pas) | LSTM / Transformer léger | Capture les dynamiques séquentielles |
| Signaux time-series, dépendance courte (< 10 pas) | XGBoost + features lag | Plus simple, souvent équivalent en performance |
| Temps réel strict (< 10 ms d’inférence), ressources limitées | Random Forest compact ou régression | Inférence rapide, déployable en edge |
Commencez toujours par le modèle le plus simple qui peut résoudre le problème. Un Random Forest qui atteint 88 % d’accuracy est souvent préférable à un LSTM qui atteint 91 %, parce que la différence de complexité en maintenance, en temps d’entraînement et en interprétabilité dépasse le gain de 3 points. Les 3 points vous coûteront plus cher à défendre en comité qu’à gagner.
Focus XGBoost — les hyperparamètres qui comptent vraiment
XGBoost est devenu le défaut implicite pour la majorité des problèmes tabulaires industriels. Il mérite ce statut. Pour autant, la différence entre un XGBoost baseline et un XGBoost bien réglé peut être énorme. Les hyperparamètres qui comptent, par ordre d’impact :
max_depth. Profondeur max des arbres. Valeurs typiques 4 à 8. Trop bas = sous-ajustement, trop haut = sur-ajustement et explosion de la mémoire. C’est le premier paramètre à tuner.
n_estimators. Nombre d’arbres. Sans early stopping, c’est l’un des pires paramètres à tuner manuellement. Avec early stopping activé (paramètre early_stopping_rounds), on le met à une valeur haute (1000 ou 5000) et on laisse la validation décider du meilleur moment où arrêter.
learning_rate. Aussi appelé eta. Valeurs typiques 0.01 à 0.3. Un learning_rate bas force plus d’arbres pour converger mais généralise mieux. Un learning_rate haut apprend vite mais est fragile.
subsample et colsample_bytree. Fraction d’exemples et de descripteurs tirés au hasard à chaque arbre. Valeurs typiques 0.7 à 0.9. Active un effet de régularisation puissant, souvent sous-utilisé.
min_child_weight. Poids minimum d’un nœud pour qu’il soit splitable. Plus la valeur est haute, plus le modèle est conservateur. Utile sur jeux de données bruités.
Le piège XGBoost n°1 en industrie : utiliser une validation croisée k-fold classique sur des données time-series. Cela revient à entraîner le modèle sur le futur pour prédire le passé, et inversement. Il faut impérativement utiliser TimeSeriesSplit (en scikit-learn) ou une validation par fenêtre glissante qui respecte l’ordre temporel.
Un modèle qui affiche 95 % en k-fold naïf et 70 % en TimeSeriesSplit n’est pas un bon modèle — c’est un modèle qui a triché sur la validation.
Focus LSTM — quand et comment
Les LSTM (Long Short-Term Memory) sont des réseaux récurrents conçus pour capturer les dépendances temporelles longues. Ils gardent une place en industrie pour les problèmes où :
- les dépendances sont longues (> 50 pas)
- le volume est suffisant (> 100K séquences)
- le budget GPU est disponible
- l’équipe client peut maintenir un environnement de deep learning — c’est souvent là que ça coince
Architecture minimum viable pour un problème de prédiction de défaut multi-capteurs : fenêtre de lookback de 60 à 300 pas temporels, 5 à 20 canaux ; couche 1 LSTM 64-128 unités avec dropout 0.2 ; couche 2 LSTM 32-64 unités avec dropout 0.2 ; couche dense finale avec activation adaptée (softmax pour classification, linéaire pour régression).
Points critiques : la normalisation doit être faite par série pour éviter qu’un capteur à forte amplitude domine l’apprentissage. Le choix de la fenêtre de lookback se tune en partant de la physique du processus — si un défaut émerge en 3 minutes à 1 Hz, 180 points est un bon point de départ.
Evaluation — au-delà de l’accuracy
L’accuracy est la métrique la plus trompeuse qu’on puisse utiliser en industrie. Sur un problème de détection de défaut où les défauts représentent 2 % des échantillons, un modèle qui prédit toujours “sain” atteint 98 % d’accuracy et n’a aucune valeur.
Les métriques à surveiller sérieusement :
Precision et recall. Sur un problème déséquilibré (défauts rares), on s’intéresse à la précision (proportion de vrais positifs parmi les prédictions positives) et au rappel (proportion de défauts réellement détectés). Le F1-score combine les deux, mais dans la plupart des cas industriels on veut pondérer asymétriquement — un défaut manqué coûte 100 fois plus cher qu’une fausse alarme, ou inversement selon le contexte. D’où l’intérêt de discuter avec le métier du coût relatif avant de choisir le seuil de décision.
RMSE vs MAE pour la régression. Pour un problème de prédiction continue (énergie consommée, durée de cycle, rendement), RMSE et MAE donnent des informations différentes. RMSE pénalise les grosses erreurs quadratiquement, MAE les pénalise linéairement. Si les grosses erreurs sont critiques (par exemple pour une prédiction de tonnage avec contrainte contractuelle), utiliser RMSE. Si les erreurs doivent être traitées uniformément, MAE.
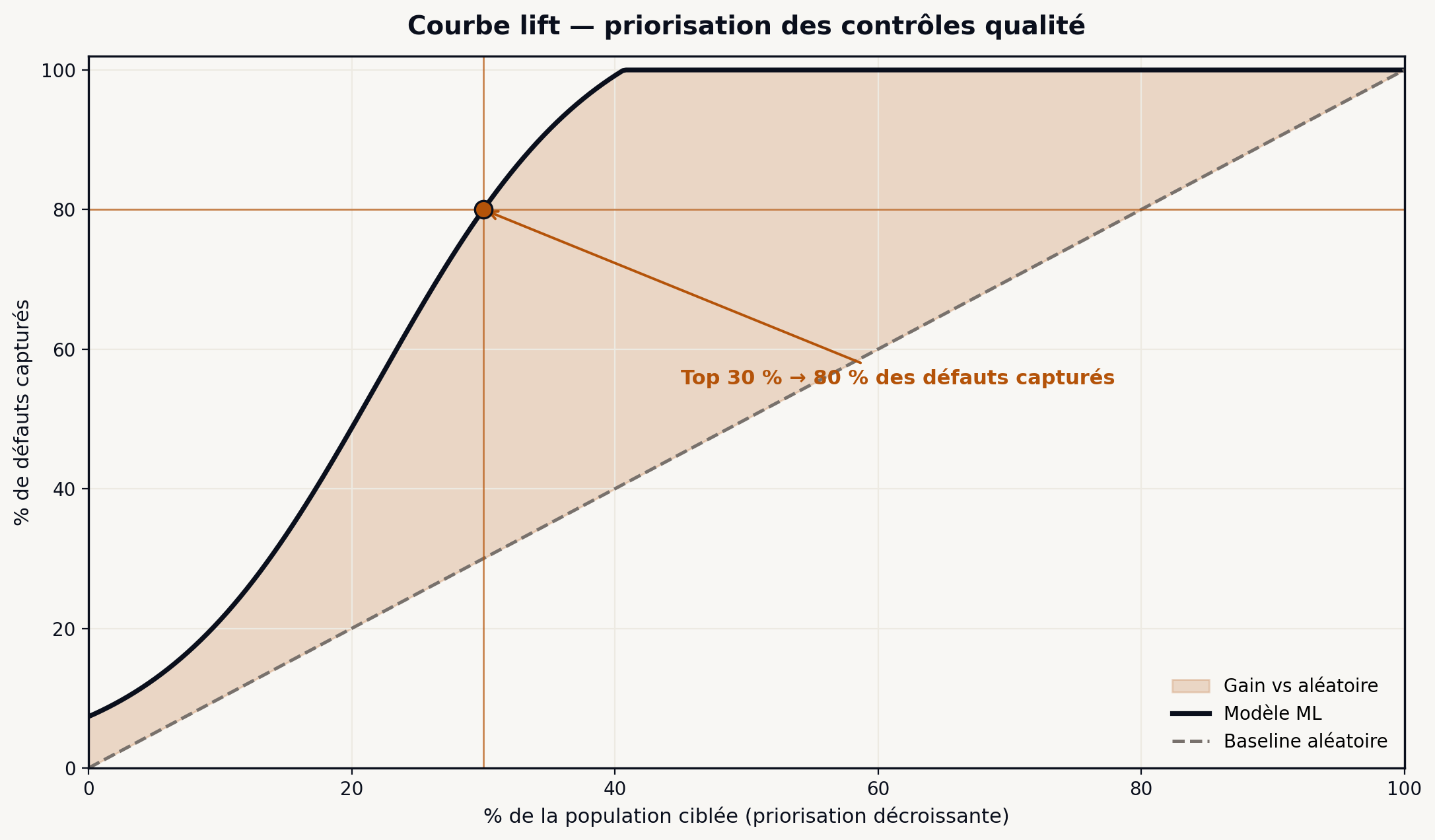
Courbe lift. Souvent ignorée, c’est pourtant la métrique la plus parlante côté business. Elle répond à la question “si j’intervenais sur les 10 % des prédictions les plus à risque selon le modèle, combien de défauts réels capterais-je ?” Un lift de 5 à 10 % signifie que le modèle concentre 50 % des défauts réels dans les 10 % des prédictions les plus à risque. Cette métrique traduit directement le ROI potentiel d’une campagne d’intervention ciblée.
Deployment — le vrai sujet qu’on évite
C’est la partie de l’article qui devrait être la plus longue mais qui est souvent expédiée. Déployer un modèle ML en production industrielle implique une série de décisions qui n’ont rien à voir avec la modélisation.
Format du modèle : ONNX vs pickle. Un modèle sauvegardé en pickle est lié à la version Python, à la version des bibliothèques, à l’ordre d’import. Il est fragile.
Un modèle exporté en ONNX (Open Neural Network Exchange) est un format ouvert, indépendant du langage, supporté par la plupart des frameworks (scikit-learn, XGBoost, PyTorch, TensorFlow). Il peut être chargé depuis du C++, du C# sur automate, du Rust sur edge device. Pour l’industrie, où les systèmes de production ne sont presque jamais en Python, ONNX est la seule option sérieuse.
Monitoring du drift. Un modèle en production dérive. Les distributions d’entrée changent (matière première, saisonnalité, usure machine), la relation entre entrée et sortie évolue. Sans monitoring, on ne le détecte qu’au moment où les utilisateurs signalent que les prédictions ne tiennent plus. Les outils de monitoring de drift (Evidently AI, NannyML, ou custom) calculent régulièrement des statistiques de distribution sur les entrées et comparent à la distribution de référence. Un alerting sur drift significatif permet d’anticiper le besoin de réentraînement.
Retraining scheduling. À quelle fréquence réentraîner le modèle ? Il n’y a pas de réponse universelle. Un pipeline robuste combine trois déclencheurs :
- Calendrier fixe (réentraînement mensuel ou trimestriel)
- Détection de drift (réentraînement quand les métriques s’écartent du référentiel)
- Dégradation métier (réentraînement quand les retours utilisateurs signalent une perte de qualité)
Chaque réentraînement doit être validé sur un jeu de test stable, jamais déployé à l’aveugle.
Versioning et rollback. Chaque version de modèle déployée doit être traçable : code, données d’entraînement, hyperparamètres, métriques de validation, date de déploiement. Si une nouvelle version se comporte mal, il doit être possible de revenir à la version précédente en quelques minutes, pas en quelques jours. Des outils comme MLflow, DVC ou des registres custom couvrent ce besoin. Pour une ETI, un registre MLflow hébergé en interne suffit dans 90 % des cas.
MLOps léger. Le mot MLOps évoque parfois des plateformes Kubernetes complexes qui découragent les ETI. Ce n’est pas obligatoire. Un MLOps léger se limite à cinq composants :
- Dépôt Git
- Registre MLflow
- Job cron de réentraînement
- Dashboard Grafana
- Script de rollback documenté
Maîtrisable par une équipe interne motivée.
Le piège n°1 — Data leakage par fuite temporelle
Si je ne devais garder qu’un avertissement dans cet article, ce serait celui-ci. Le data leakage est le moment où des informations du futur se glissent dans les données d’entraînement du modèle. En time-series, il prend plusieurs formes redoutables :
-
Normalisation globale. Si vous normalisez l’ensemble avant de splitter train/val/test, les statistiques du train contiennent déjà l’information du test. Calculer les stats uniquement sur le train, puis appliquer au test.
-
Features construites sur le futur. Une “moyenne mobile centrée sur 60 secondes” à l’instant t utilise des valeurs de t+30. En backtest ça marche. En production, le modèle s’effondre.
-
Validation croisée k-fold naïve. k-fold aléatoire sur time-series est une faute professionnelle. Un modèle qui voit le 15 mars en train et prédit le 10 mars en test a triché.
-
Labels antérieurs à l’entrée. Subtil et vicieux : si le pipeline de labellisation utilise une information disponible seulement après l’événement (rapport qualité à J+2), le modèle en production ne pourra pas utiliser ces labels au moment de la prédiction.
Test de détection du leakage : pour chaque descripteur et chaque label, demandez-vous “si j’étais en production à l’instant t, aurais-je accès à cette information ?” Si la réponse est non, c’est une fuite. Si la réponse est oui mais avec un délai (par exemple une mesure labo disponible 4 h après), il faut le modéliser explicitement dans le pipeline.
Ce que BCUB3 fait différemment
Notre approche du ML industriel tient en quatre points :
1. Déployable en local. Pas de cloud obligatoire. Les modèles tournent sur les serveurs du client, souvent dans le périmètre IT déjà maîtrisé. La souveraineté des données est un critère prioritaire pour la plupart des industriels français, et c’est un choix par défaut chez nous.
2. Formats ouverts. ONNX systématique pour les modèles de production. Pas de dépendance à un SaaS propriétaire qu’il faudrait payer à vie.
3. Documentation opérationnelle obligatoire. Chaque modèle est livré avec une fiche qui décrit : quelles données sont attendues en entrée, à quelle fréquence, quel est le format de sortie, comment interpréter les prédictions, quel est le protocole en cas de drift détecté, qui contacter. Sans cette fiche, le modèle n’est pas considéré comme livré.
4. Transfert de compétences. Nous formons les équipes client à maintenir le pipeline, pas seulement à l’utiliser. L’objectif est qu’à la fin de la mission, l’équipe interne puisse ajouter une nouvelle variable, relancer un entraînement, diagnostiquer une dérive. Notre indicateur de succès n’est pas la précision du modèle, c’est le jour où le client n’a plus besoin de nous.
Pour aller plus loin
Le machine learning industriel n’est pas une révolution qui remplace les méthodes existantes. C’est une extension qui permet de capter des patterns invisibles aux outils classiques, à condition d’être appliquée sur un processus déjà maîtrisé et avec des données propres. L’erreur la plus fréquente est d’attaquer un projet ML sur un processus chaotique : on finit par automatiser le chaos.
Pour comprendre comment le ML se combine avec les méthodes Lean Six Sigma sans les remplacer, voir l’article Lean Six Sigma × Machine Learning : le combo qui change la donne. Et pour les fondamentaux statistiques qui restent indispensables même avec un modèle ML derrière, l’article Lean Six Sigma : les statistiques qui comptent vraiment couvre les outils qu’on utilise au quotidien sur chaque mission.