La fausse opposition Lean vs ML
Il existe une ligne de fracture intellectuelle dans le monde de la performance industrielle, et elle est fausse. D’un côté, les tenants du Lean Six Sigma “pur” qui regardent les modèles ML avec suspicion — “boîtes noires”, “hype passagère”. De l’autre, les adeptes de la data science qui considèrent le Six Sigma comme vieillot — “pourquoi faire une ANOVA quand un XGBoost fait mieux en trois lignes de Python”.
Les deux camps ont tort. Le Lean apporte la discipline du processus : méthode éprouvée pour structurer un problème, mobiliser des équipes, maintenir des gains. Le ML apporte la capacité de voir : détection de patterns dans des données multivariées que les outils classiques ratent.
Un processus sans discipline ne tire aucune valeur d’un modèle ML, parce que les gains s’évaporent dès qu’on cesse de le maintenir. Un processus sans détection avancée plafonne à ce que l’oeil humain et la carte Shewhart peuvent voir. La combinaison n’est pas un compromis, c’est la solution.
Cet article décrit comment le ML augmente chaque étape DMAIC sans remplacer les outils Lean classiques, et se conclut sur un cas d’usage bout-en-bout anonymisé.
DMAIC classique vs augmenté ML
| Étape | Classique | Augmenté ML |
|---|---|---|
| Define | Charte de projet, SIPOC, Voix Client | Inchangé — le problème est humain |
| Measure | Plan de collecte, capabilité Cp/Cpk, SPC | Détection d’anomalie multivariée, autoencoder |
| Analyze | ANOVA, diagramme Ishikawa, 5 pourquoi | ANOVA + SHAP pour les modèles complexes |
| Improve | DOE factoriel, Taguchi | Optimisation bayésienne quand les essais coûtent cher |
| Control | Cartes Shewhart, plans de surveillance | Cartes de contrôle adaptatives, alarmes apprises |

Les sections qui suivent détaillent chaque ligne du tableau, avec la nuance qui compte : quand le ML apporte vraiment quelque chose, et quand c’est du bruit.
Define — où le ML n’aide pas
Contre-intuition utile. À l’étape Define, le ML n’a rien à apporter. C’est une étape humaine, conversationnelle, politique : formaliser un problème, délimiter un périmètre, identifier les parties prenantes. Aucune technique d’apprentissage ne peut remplacer une réunion bien menée avec le chef de production, le responsable qualité et le directeur industriel.
La tentation existe quand même. On voit parfois des équipes vouloir “laisser les données parler” dès le début, en lançant des analyses exploratoires avant d’avoir défini le problème. C’est du temps perdu. Le Lean Six Sigma sait faire cette étape depuis 30 ans. Ne forcez pas le ML là où il n’a pas sa place.
Measure — détection d’anomalie multivariée
C’est à l’étape Measure que le ML commence à apporter une vraie différence. Les outils classiques de SPC — cartes Shewhart, cartes EWMA, cartes CUSUM — sont excellents pour surveiller une variable à la fois, ou au mieux quelques variables liées par une relation connue. Ils sont aveugles aux anomalies multivariées : un état du processus où chaque variable individuelle reste dans ses limites, mais où la combinaison des variables est anormale.
Exemple classique dans une ligne de thermoformage : la température du bain chauffant est à 175 °C (dans la plage), la vitesse de ligne est à 12 m/min (dans la plage), l’humidité ambiante est à 62 % (dans la plage). Chaque variable prise isolément est normale.
Mais cette combinaison n’est jamais apparue dans les six derniers mois de production sans défaut. Une carte Shewhart sur chaque variable ne déclenchera rien. Un modèle de détection d’anomalie multivariée, lui, verra cette combinaison comme un point très éloigné de la distribution d’entraînement.
Les deux familles de modèles qui fonctionnent bien pour cette tâche :
Isolation Forest. Algorithme non supervisé qui isole les points anormaux en construisant des arbres aléatoires. Les points anormaux sont typiquement isolés en peu de splits (peu profondément dans l’arbre). Léger, rapide, interprétable, très adapté aux ETI avec une infrastructure modeste. Hyperparamètres à ajuster : contamination (estimation a priori du taux d’anomalies) et n_estimators (nombre d’arbres).
Autoencoder. Réseau de neurones qui apprend à reconstruire ses entrées en passant par un goulot dimensionnel. Les échantillons normaux sont bien reconstruits, les échantillons anormaux ont une erreur de reconstruction élevée. Plus puissant qu’Isolation Forest sur signaux de grande dimension, plus lourd à entraîner et à maintenir.
La bonne pratique n’est pas de remplacer la carte Shewhart par un modèle ML, mais de les superposer. La carte Shewhart couvre les défauts univariés avec la rigueur statistique qu’on lui connaît. Le modèle de détection d’anomalie couvre les défauts multivariés qui échappent à la carte. Les deux alarmes alimentent le même dashboard, avec des codes couleur différents pour distinguer les origines.
Cas concret : sur une ligne de thermoformage, un défaut émergent lié à une combinaison humidité/température/lot matière a été détecté par un autoencoder 12 heures avant la première dérive Cpk visible sur la carte classique. Les 12 heures d’avance ont permis de corriger avant qu’aucune pièce non conforme ne sorte. C’est le type de résultat qu’on n’obtient avec aucune des deux approches seule.
Analyze — ANOVA plus SHAP
L’ANOVA reste la meilleure technique pour établir la significativité statistique d’un effet entre groupes. C’est une méthode rigoureuse, interprétable, et elle tient depuis un siècle. Le ML ne remplace pas l’ANOVA. Mais il la complète utilement quand le problème devient non linéaire et que plusieurs variables interagissent de façon complexe.
C’est là qu’intervient SHAP (SHapley Additive exPlanations). SHAP est une technique d’explication de prédictions issue de la théorie des jeux coopératifs. Pour chaque prédiction d’un modèle complexe (XGBoost, Random Forest, réseau de neurones), SHAP calcule la contribution de chaque descripteur à la prédiction, en tenant compte de toutes les interactions entre descripteurs. Le résultat est une décomposition additive de la prédiction en contributions individuelles.
En pratique industrielle, on utilise SHAP de deux façons :
Global. Pour comprendre quels sont les descripteurs les plus influents sur l’ensemble des prédictions du modèle. Le summary plot SHAP remplace avantageusement le feature importance classique des forêts aléatoires, en ajoutant la direction de l’effet et la distribution des contributions.
Local. Pour expliquer une prédiction particulière — typiquement une alarme levée par le modèle de détection d’anomalie. Le waterfall plot SHAP montre, pour cet échantillon précis, quels descripteurs ont poussé le modèle à prédire “anomalie” et dans quelle proportion.
C’est un outil de diagnostic qui change la conversation en salle de pilotage : au lieu de “le modèle a détecté quelque chose”, on a “le modèle a détecté une combinaison entre humidité à 68 % et vitesse ligne à 11.5 m/min, et cette combinaison contribue à 73 % du score d’anomalie”.
Le piège à éviter : SHAP n’est pas une preuve de causalité. SHAP attribue des contributions à la prédiction d’un modèle, pas à la réalité physique du processus. Si le modèle a appris une corrélation spurious (corrélation fortuite sans lien causal), SHAP la reflètera fidèlement.
L’ANOVA garde l’avantage méthodologique d’un vrai test statistique d’effet, à condition d’être appliquée sur des données issues d’un plan d’expérience contrôlé. Les deux outils sont complémentaires : ANOVA pour établir la causalité à petit nombre de facteurs, SHAP pour explorer les interactions dans les modèles complexes.
Improve — optimisation bayésienne contre DOE factoriel
Le DOE factoriel reste le meilleur outil d’amélioration quand les essais sont peu coûteux et que le nombre de facteurs est limité. Un plan 2^3 avec 8 essais est souvent faisable en quelques heures de production et donne des résultats robustes. Mais dès que chaque essai coûte cher — 500 €, 4 heures de production, arrêt de ligne, consommation de matière — le plan factoriel devient prohibitif.
Cas concret : une machine de remplissage multi-têtes avec 6 paramètres, 5 niveaux chacun. Un plan complet exigerait 5^6 = 15 625 essais. Un plan fractionnaire agressif descend à plusieurs centaines d’essais. À 500 € l’essai, c’est inenvisageable.
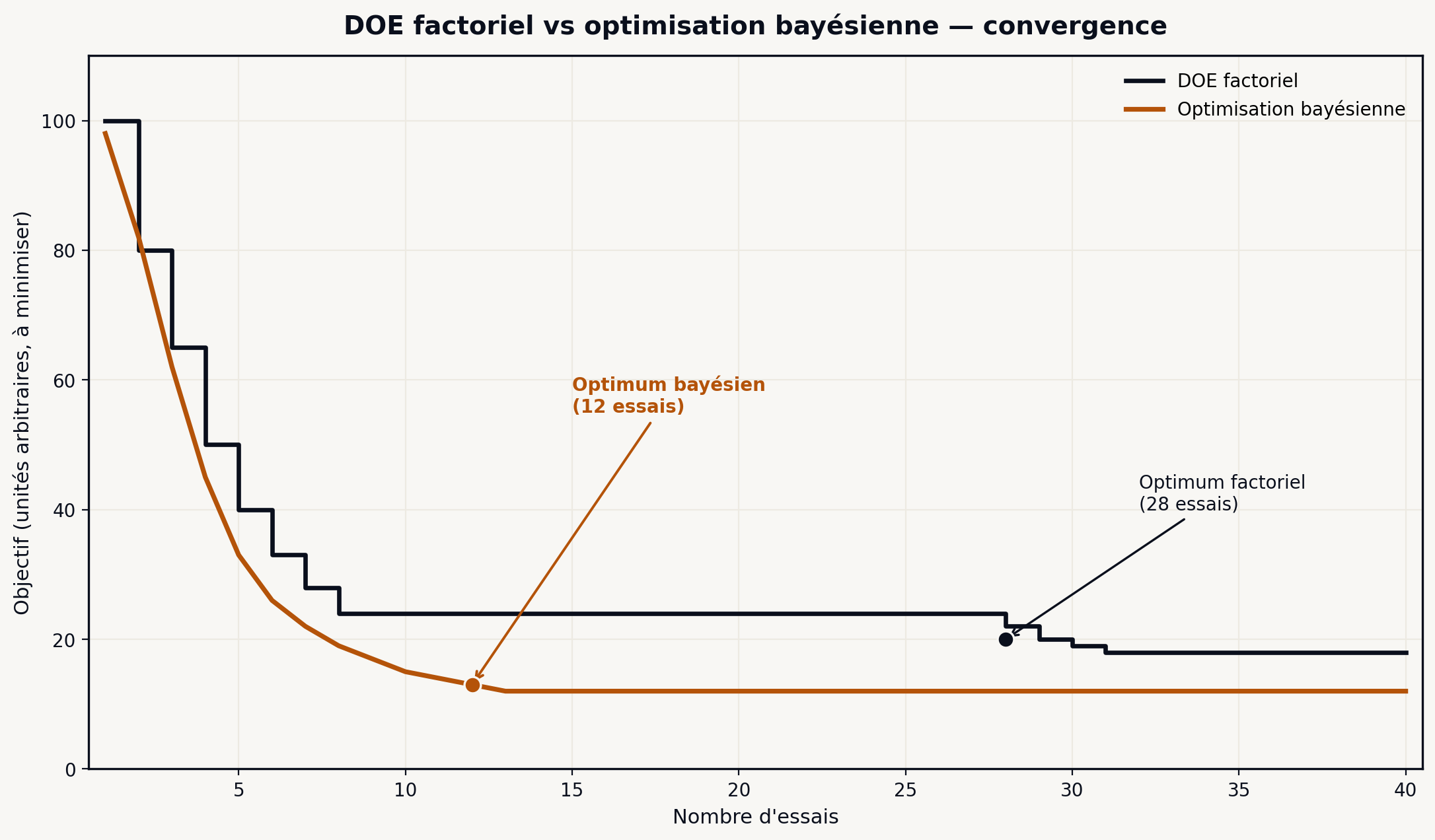
L’optimisation bayésienne est la technique adaptée. Le principe : on construit un modèle probabiliste (typiquement un processus gaussien) qui approxime la fonction “paramètres → rendement”, et à chaque étape on choisit le prochain essai pour maximiser l’information apportée au modèle. Les essais sont placés intelligemment et le modèle converge vers l’optimum en 8 à 15 essais.
Les frameworks Python matures (Optuna, scikit-optimize, BoTorch) permettent d’appliquer cette technique avec un effort raisonnable. La limite : la réponse doit être numérique, continue, avec un nombre de facteurs modéré (jusqu’à 15-20) et des contraintes exprimables.
Préférer l’optimisation bayésienne au DOE factoriel quand quatre critères sont réunis :
- Coût d’essai élevé (> 100 EUR ou 2 h)
- Espace large (> 4 facteurs, > 3 niveaux)
- Fonction de réponse lisse
- Budget d’essais contraint (< 30)
Sinon, restez sur le DOE factoriel — plus simple, interprétable, maintenable par l’équipe client.
Control — cartes de contrôle adaptatives
Les cartes de contrôle classiques supposent une moyenne et un écart-type cible fixes. Dans beaucoup de processus industriels modernes, cette hypothèse ne tient pas. Les limites de contrôle varient selon le produit fabriqué, le lot matière en cours, la saison, l’équipe en poste. Une carte Shewhart figée déclenche soit trop d’alarmes (si les limites sont trop serrées pour couvrir la variabilité légitime), soit trop peu (si elles sont relâchées pour s’adapter à la variabilité maximale).
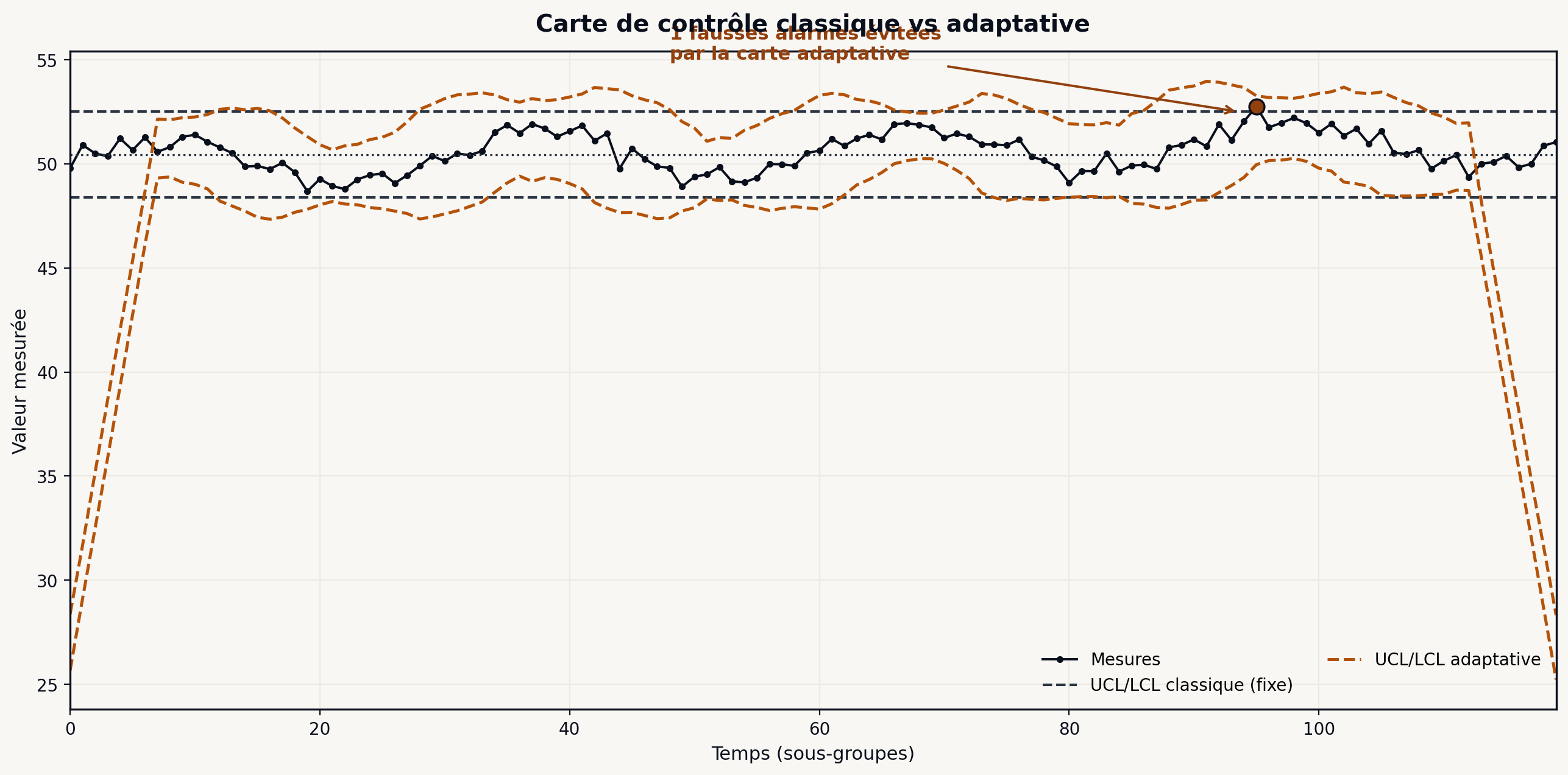
La carte de contrôle adaptative apprend la relation entre les variables de contexte (produit, lot, équipe, horaire, conditions ambiantes) et la valeur moyenne attendue de la variable surveillée. À chaque instant, le modèle prédit la valeur attendue et son écart-type contextuel, et la carte trace les limites autour de cette prédiction plutôt qu’autour d’une constante fixe. Le modèle sous-jacent est en général un simple régresseur (XGBoost ou Random Forest) entraîné sur l’historique.
Le résultat : beaucoup moins de faux positifs dans les transitions de produit ou de lot, et une sensibilité accrue aux vraies dérives qui apparaissent indépendamment du contexte. Les opérateurs reprennent confiance dans la carte, les alarmes redeviennent crédibles, et le système de surveillance retrouve son utilité.
Point d’attention : une carte adaptative est un modèle ML en production, avec toutes les obligations de maintenance qui vont avec. Monitoring du drift, réentraînement périodique, documentation opérationnelle. Elle n’est pas “installable et oubliée”. Si le client n’a pas la capacité de maintenir un modèle ML sur le long terme, il vaut mieux rester sur une carte Shewhart fiable, même moins précise.
Cas d’usage bout-en-bout
Prenons un cas anonymisé : un transformateur de matières plastiques fabriquant des moules techniques pour l’industrie agroalimentaire. Problématique : taux de rebut de 4.2 % sur une référence critique, pression commerciale pour le ramener à 1.5 % en six mois. Budget mission : consultant à temps partiel, pas de recrutement interne supplémentaire.
Define. Workshop d’une journée avec le chef de production, le responsable qualité et le directeur industriel. Formalisation de la charte projet, SIPOC de la ligne concernée, identification des deux modes de défaillance dominants (brûlure de matière et déformation post-moulage) qui représentent 80 % des rebuts. Choix de se concentrer sur la brûlure de matière en phase 1. Outil Lean classique, aucun ML.
Measure. Collecte d’un mois de données : 18 capteurs sur la ligne (températures 4 zones, pressions, vitesses, humidité, températures matière, paramètres d’injection), horodatés à la seconde, liés aux numéros de pièces et aux contrôles qualité en fin de ligne. Calcul de la capabilité actuelle sur les 6 paramètres critiques. Installation d’une carte X-bar R classique sur les deux paramètres principaux. Ajout ML : entraînement d’un autoencoder sur les données “sain” du dernier mois, déploiement en monitoring temps réel avec alerting sur écart de reconstruction.
Analyze. ANOVA à un facteur sur les six paramètres critiques, confirmation statistique que trois d’entre eux (température zone 3, pression tête 2, vitesse vis) ont un effet significatif sur le taux de brûlure. Ajout ML : entraînement d’un XGBoost prédictif sur la variable binaire “brûlure observée / non observée” sur les 4 semaines d’historique, puis analyse SHAP globale qui révèle une interaction entre température zone 3 et humidité ambiante — interaction que l’ANOVA n’avait pas testée parce qu’elle n’était pas dans le plan initial. Cette découverte devient une hypothèse à tester en phase Improve.
Improve. Au lieu d’un DOE factoriel 2^4 (16 essais sur ligne en production, coût estimé 8 000 €), on lance une optimisation bayésienne sur les 4 paramètres retenus, avec une fonction objectif = taux de brûlure estimé sur un échantillon de 200 pièces par réglage. Convergence en 12 essais, coût total 6 000 €, réduction modélisée du taux de brûlure de 4.2 % à 1.8 %.
Control. Déploiement d’une carte de contrôle adaptative sur la température zone 3, avec prise en compte de l’humidité ambiante et du lot matière en entrée. Maintien de la carte Shewhart classique en parallèle sur les deux paramètres principaux pour ne pas rompre les habitudes de l’équipe. Mise en place d’un dashboard Grafana consulté en poste, avec alerting unifié sur les deux systèmes. Formation de deux opérateurs et du responsable qualité à la maintenance du modèle (réentraînement mensuel, interprétation des alertes SHAP). Transfert de connaissance documenté sur 6 pages maximum — pas de slide deck de 80 pages.
Résultat à 4 mois. Taux de rebut mesuré à 1.6 %, gain annuel net estimé à 185 k EUR. L’équipe maintient le pipeline de façon autonome. Le consultant intervient 1 jour par mois en check-up pour les 6 mois suivants.
Ce sont les deux approches combinées, chacune apportant ce qu’elle sait faire mieux que l’autre, qui donnent le résultat. Le transfert de compétences fait que le gain ne disparaît pas avec la fin de la mission.
Le piège n°1 — empiler le ML sur un processus non maîtrisé
Si je n’avais qu’un avertissement à donner sur ce sujet, ce serait celui-là. On voit régulièrement des projets ML lancés sur des processus chaotiques, dans l’espoir que “le modèle saura démêler ça tout seul”. Il ne le saura pas.
Un modèle ML entraîné sur un processus non maîtrisé apprend le chaos. Il apprend les corrélations fortuites entre variables qui bougent ensemble parce que personne ne pilote rien, pas parce qu’il y a une relation causale.
Il produit des prédictions fragiles qui tombent dès que le processus change légèrement d’équilibre. Et il transforme une absence de contrôle en fausse confiance technologique — “on a un modèle IA qui surveille la ligne” — ce qui est pire que de ne rien avoir du tout.
La règle est : Lean d’abord, ML ensuite. On met le processus sous contrôle avec les outils Lean classiques, on établit une base de référence stable, on améliore ce qui doit l’être. Seulement alors, on introduit les techniques ML pour aller chercher la couche supplémentaire de détection et d’optimisation. Dans l’autre sens, ça ne marche pas.
La vraie question à poser en steering
Avant chaque décision d’introduire un modèle ML dans un projet d’amélioration continue, il y a une question que nous posons systématiquement en comité de pilotage : “Ce que le ML apporte ici, est-ce qu’on pourrait l’obtenir avec une bonne carte de contrôle et 3 heures de revue process ?”
Souvent, la réponse est oui. Dans ce cas, on économise le ML, on ne lance pas un projet technique qui introduit de la complexité sans valeur proportionnelle, et on fait mieux le Lean. Parfois, la réponse est non — typiquement quand le problème est réellement multivarié, quand les dynamiques sont trop lentes ou trop rapides pour l’œil humain, quand le coût des essais exige une approche guidée. Dans ce cas, le ML est justifié et on l’introduit avec l’exigence opérationnelle qui va avec.
L’honnêteté de la réponse à cette question fait toute la différence entre un projet utile et un projet de signalement technologique. C’est un arbitrage qui doit être refait à chaque mission, pas une doctrine d’école.
La méthode BCUB3 — Lean-first, ML-when-justified
Notre approche tient en trois principes :
Lean-first. Aucun projet ML n’est lancé avant que le processus soit sous contrôle avec les outils Lean classiques. Si la maturité n’est pas là, on commence par le Lean, et on introduit le ML plus tard — ou jamais.
ML-when-justified. Le ML n’est pas introduit par principe, mais par nécessité. Chaque brique ML est justifiée par une incapacité démontrée des outils classiques. Si l’ANOVA et le DOE factoriel suffisent, on s’arrête là. L’élégance méthodologique n’a jamais amélioré un ROI.
Toujours transférable. Ce qu’on met en place doit pouvoir être maintenu par l’équipe client. Formats ouverts, documentation opérationnelle, formation incluse, complexité limitée. Un modèle brillant que personne ne sait maintenir est un échec différé.
La combinaison Lean Six Sigma × Machine Learning n’est pas un gadget. Bien appliquée, elle permet de franchir des paliers inaccessibles à l’une des deux approches seule. Mal appliquée, elle empile les inconvénients des deux. La différence tient à la discipline d’exécution et à l’honnêteté des arbitrages.
Pour aller plus loin
Les fondements statistiques du Lean Six Sigma — capabilité, SPC, ANOVA, DOE — restent la base de travail indispensable, même avec des modèles ML derrière. L’article Lean Six Sigma : les statistiques qui comptent vraiment détaille les sept statistiques qui comptent vraiment en production.
Sur le pendant ML du pipeline — CRISP-DM appliqué aux signaux industriels, choix des modèles, et le vrai sujet du déploiement en production — l’article Machine Learning pour l’industrie : du signal au modèle en production couvre les pièges qu’on évite rarement sans expérience terrain, notamment la question du data leakage temporel et du MLOps léger en ETI.