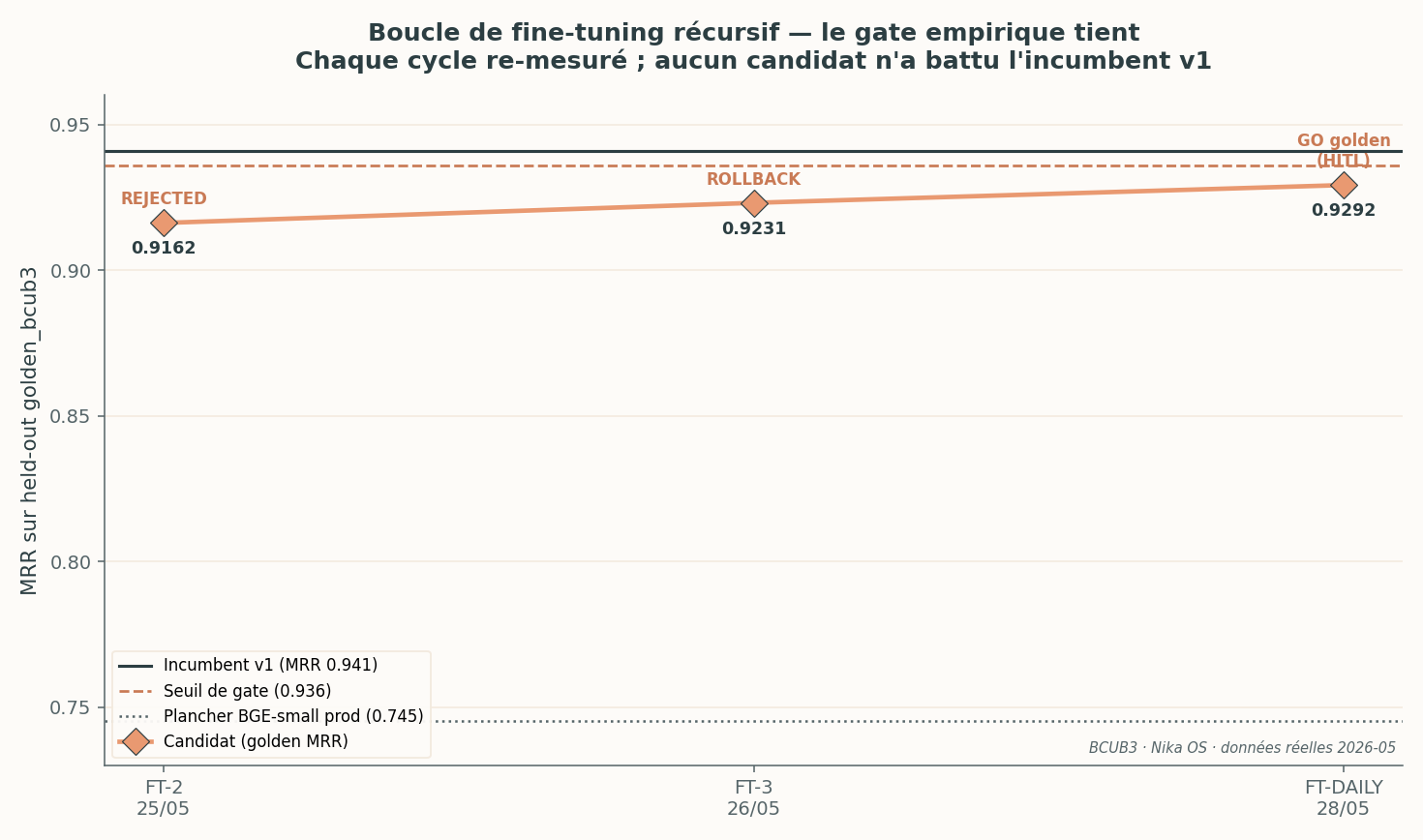
 Trois cycles de fine-tuning récursif. Aucun candidat n’a franchi le seuil de l’incumbent v1 — le gate empirique a refusé chaque promotion. C’est le système qui fonctionne, pas qui échoue.
Trois cycles de fine-tuning récursif. Aucun candidat n’a franchi le seuil de l’incumbent v1 — le gate empirique a refusé chaque promotion. C’est le système qui fonctionne, pas qui échoue.
TL;DR
Le fine-tuning récursif consiste à ré-entraîner en boucle le modèle qui transforme vos textes en vecteurs (les embeddings), à mesurer le gain réel sur un jeu de test, et à ne promouvoir une nouvelle version que si elle bat l’ancienne — chiffres à l’appui. Sur Nika OS, chaque cycle suit la même discipline : entraînement LoRA sur e5-base, évaluation sur un golden set tenu à l’écart, contrôle de l’oubli généraliste, puis cutover ou rollback.
Les chiffres réels mesurés : le passage de BGE-small (production) à e5-base fine-tuné fait gagner +0,184 de MRR et +15 points de Recall@10 sur le golden BCUB3 (n=100). Mais sur trois cycles successifs, aucun candidat n’a battu l’incumbent v1 (MRR 0,9408) — le système les a tous refusés. Et la traque de l’oubli catastrophique — le paradoxe de Funès appliqué au modèle — a montré qu’une tranche de test trop petite (n=40) déclenche un faux signal d’alerte qui disparaît dès qu’on double l’échantillon (n=80). La leçon centrale : mesurer avant d’adopter ; un modèle qui « semble meilleur » sans chiffre n’a pas le droit de partir en production.
Qu’est-ce que le fine-tuning récursif des embeddings ?
L’embedding, brique de base du RAG
Un agent comme Nika ne « lit » pas vos documents à chaque question. Il les a au préalable transformés en embeddings : des vecteurs numériques (ici de 384 ou 768 dimensions) qui encodent le sens d’un passage. Quand vous posez une question, elle est elle-même transformée en vecteur, et le système ramène les passages dont le vecteur est le plus proche. C’est le cœur du RAG (Retrieval-Augmented Generation) : on retrouve avant de répondre, pour ancrer la réponse dans des faits plutôt que dans l’imagination du modèle.
La qualité de tout l’édifice dépend donc d’une seule chose : est-ce que le modèle d’embeddings place les bons documents près des bonnes questions ? Un modèle générique (entraîné sur le web) connaît le monde mais ignore tout de votre vocabulaire interne — vos clients, vos process, vos acronymes maison. D’où l’idée de le spécialiser.
Pourquoi ré-entraîner en boucle
Le corpus d’une organisation vivante n’est pas figé : chaque jour de nouveaux e-mails, devis, comptes-rendus, sessions de travail s’ajoutent. Un modèle fine-tuné une fois en mai sera légèrement décalé en juillet. Le fine-tuning récursif répond à cette dérive : à intervalle régulier (ici, un cycle quotidien FT-DAILY), on ré-entraîne sur les données fraîches, on re-mesure, et on décide.
Le mot important est on décide. Une boucle qui ré-entraîne et promeut automatiquement, sans gate, ne fait pas de l’apprentissage : elle fait de la dérive. La récursivité n’a de valeur que parce qu’elle est encadrée par une mesure qui peut dire non.
LoRA : spécialiser sans tout casser
On ne ré-entraîne pas les 110 millions de paramètres du modèle de base à chaque cycle — ce serait coûteux et dangereux. On utilise LoRA (Low-Rank Adaptation) : le modèle d’origine est gelé, et on n’entraîne que de petites matrices de rang faible greffées par-dessus. Configuration réelle des cycles Nika :
| Paramètre | Valeur |
|---|---|
| Modèle de base | intfloat/multilingual-e5-base (gelé) |
| LoRA rank / alpha / dropout | 16 / 32 / 0,1 |
| Learning rate | 2 × 10⁻⁵ |
| Epochs | 3 |
| Batch size | 32 |
| Warmup steps | 100 |
| Weight decay | 0,01 |
| Température (contrastive) | 0,02 |
| Seed | 42 (déterministe) |
| Paires d’entraînement | 11 058 |
| Matériel | NVIDIA A100 80 Go |
| Durée | 716 s (~12 min) |
| Coût | ~0,31 $/cycle |
Le fait que le backbone reste gelé est la première protection contre l’oubli catastrophique : la dérive des poids est bornée par construction. On y revient plus bas.
Lire les indicateurs sans être data scientist
Avant les courbes, posons le vocabulaire. Ces quatre indicateurs reviennent partout dans l’article.
Recall@k — « ai-je ramené la bonne info ? »
Le Recall@k est la proportion de questions pour lesquelles le bon document figure dans les k premiers résultats. Recall@1 = le bon document est en première position. Recall@10 = il est quelque part dans les dix premiers. C’est une mesure de couverture : peu importe la position exacte, l’info est-elle là ?
MRR — « est-elle classée HAUT ? »
Le MRR (Mean Reciprocal Rank) raffine le Recall en récompensant la position. Pour chaque question, on prend 1 / rang du premier bon résultat, puis on moyenne. Bon document en position 1 → 1,0 ; en position 2 → 0,5 ; en position 4 → 0,25. Un retriever qui ramène la bonne réponse mais en 8ᵉ position a un bon Recall@10 et un mauvais MRR. Pour un RAG, le MRR est l’indicateur roi, car le LLM lit surtout les premiers passages.
nDCG — « le classement est-il propre ? »
Le nDCG (Normalized Discounted Cumulative Gain) va encore plus loin : il pénalise logarithmiquement chaque bonne réponse placée en bas de liste et normalise le tout entre 0 et 1. Il tient compte de la position et d’une pertinence graduée. C’est le plus fin des trois.
Effect size vs p-value — « le gain est-il réel ou du bruit ? »
Deux questions distinctes, qu’on confond souvent :
- La p-value répond à « ce résultat est-il dû au hasard ? ». Une p-value faible dit « probablement pas du hasard ».
- L’effect size (taille d’effet) répond à « est-ce que c’est gros ? ». Un gain peut être statistiquement détectable mais minuscule, donc sans intérêt pratique.
Une p-value sans effect size est du bruit, et un effect size sur un échantillon minuscule est fragile. Vous verrez plus bas un cas réel où un écart de −0,027 sur 40 questions déclenche une alerte qui s’évapore dès qu’on passe à 80 questions : la taille de l’échantillon, pas seulement le signe de l’écart, décide.
La métrique d’oubli généraliste — « ai-je perdu mes acquis ? »
Quand on spécialise un modèle sur un corpus singulier, il risque d’oublier ce qu’il savait faire en généraliste. On mesure donc, en plus du golden BCUB3, le MRR sur une tranche généraliste tenue à l’écart (extraite de MS-MARCO, jamais vue à l’entraînement). Si ce MRR généraliste chute trop, c’est un signal d’oubli catastrophique — et un motif de refus de promotion.
Les courbes réelles
Toutes les valeurs ci-dessous proviennent des journaux d’entraînement et d’évaluation réels de Nika OS (
continuous_ft_history.jsonl,results_finetune.json,gate_eval.json,forgetting_eval.json). Aucun chiffre n’est reconstitué.
Progression par epoch
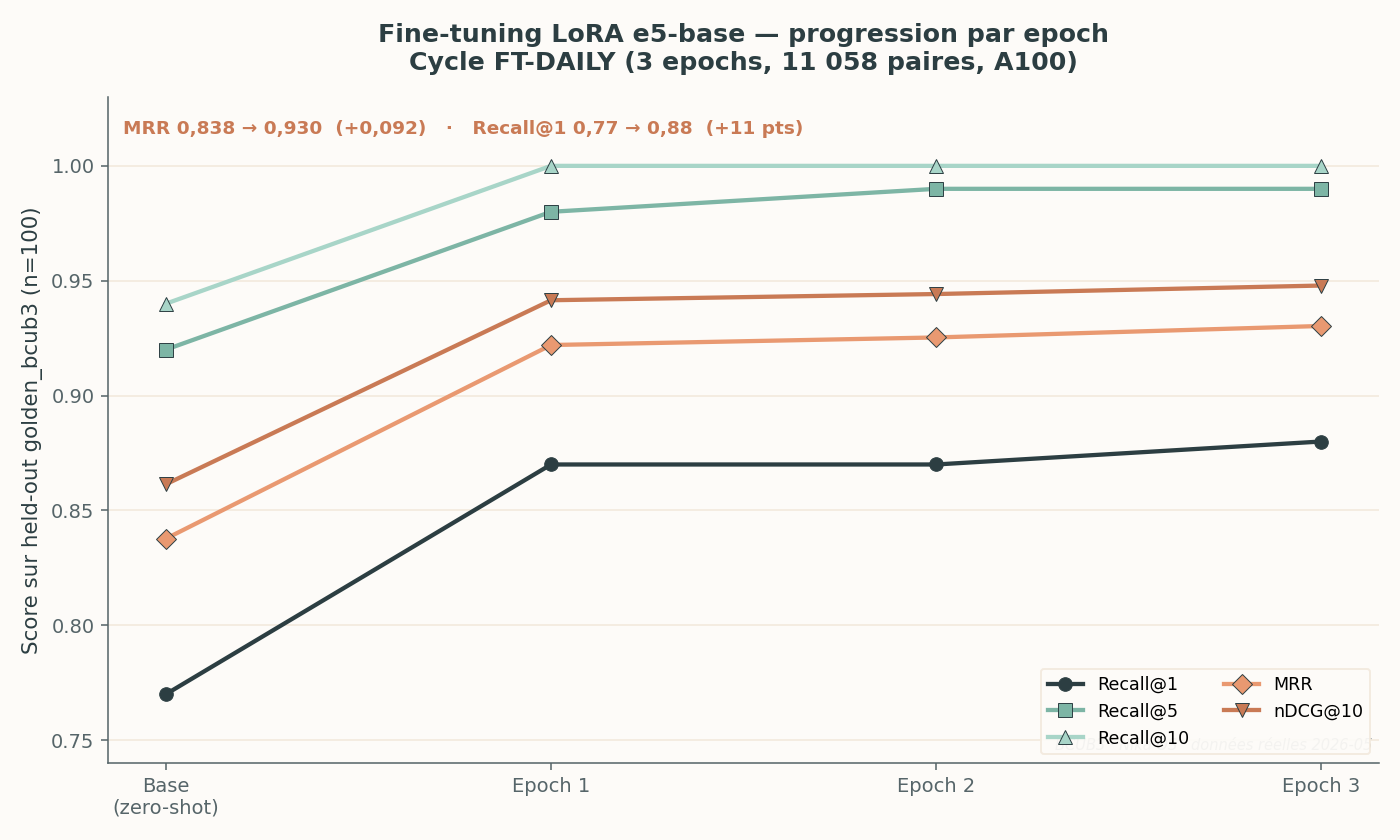 Cycle FT-DAILY du 28/05 : e5-base zero-shot (point « Base ») puis trois epochs de LoRA. Le MRR passe de 0,838 à 0,930.
Cycle FT-DAILY du 28/05 : e5-base zero-shot (point « Base ») puis trois epochs de LoRA. Le MRR passe de 0,838 à 0,930.
Sur le cycle FT-DAILY-2026-05-28, le modèle de base (e5-base sans fine-tune) part déjà à MRR 0,838 sur le golden, et le fine-tuning LoRA le porte à 0,930 en trois epochs (+0,092). Le Recall@10 atteint 1,0 dès l’epoch 1 — et y reste : le golden sature (on y revient dans les limites). Le Recall@1, lui, continue de progresser jusqu’à 0,88, ce qui confirme que le gain n’est pas qu’une illusion de plafond.
Gains vs baseline de production
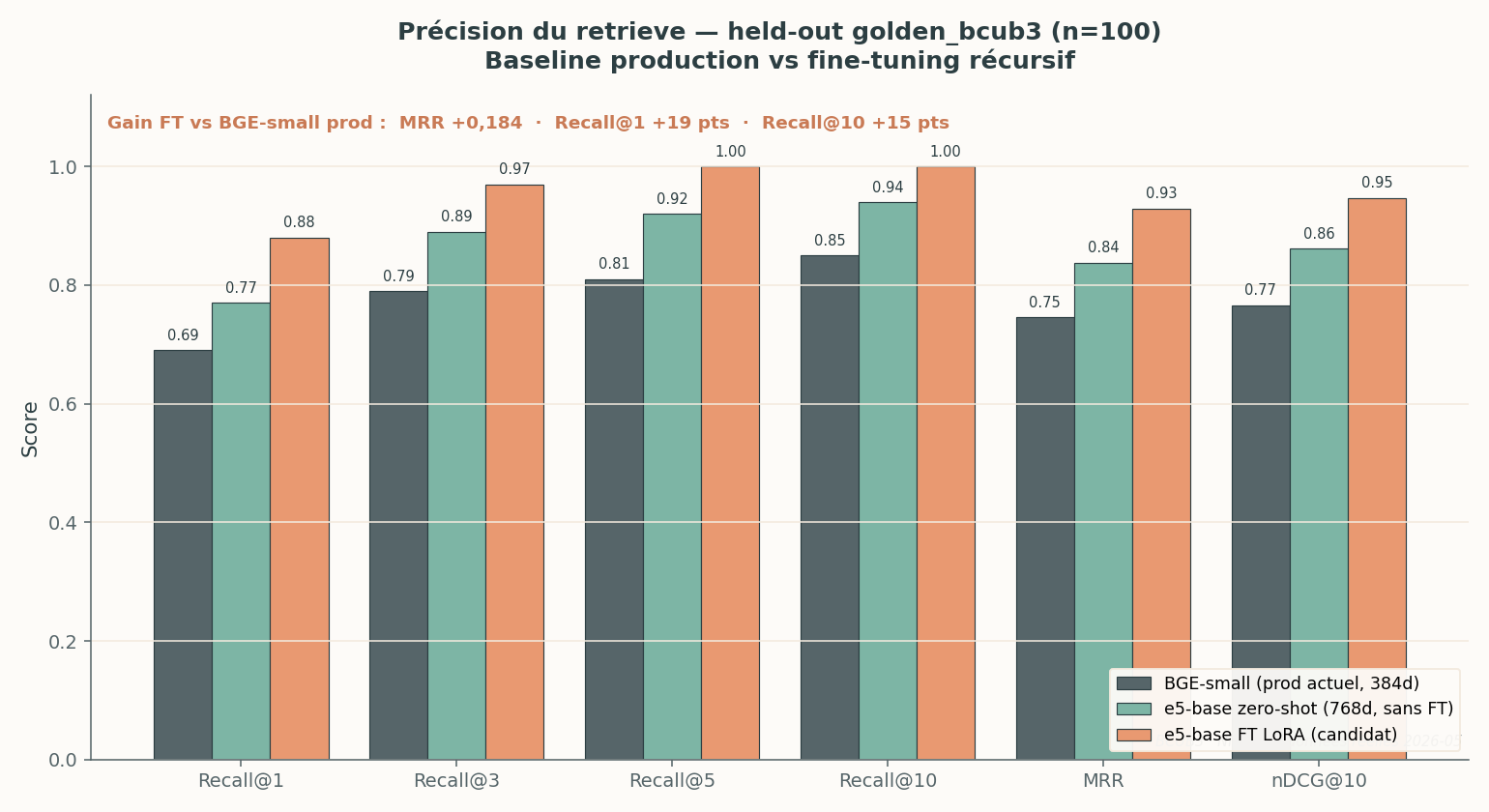 Trois modèles sur le même golden n=100. Le gain se décompose : la moitié vient du changement de modèle de base (BGE → e5), l’autre du fine-tuning.
Trois modèles sur le même golden n=100. Le gain se décompose : la moitié vient du changement de modèle de base (BGE → e5), l’autre du fine-tuning.
C’est la figure la plus importante pour juger l’intérêt de l’opération. Trois colonnes :
- BGE-small (le modèle en production aujourd’hui, 384 dimensions) : MRR 0,745 sur ce golden.
- e5-base zero-shot (768 dimensions, sans fine-tune) : MRR 0,838.
- e5-base fine-tuné LoRA (le candidat) : MRR 0,929.
Le gain total du candidat sur la production est de +0,184 de MRR, +19 points de Recall@1 et +15 points de Recall@10. Détail honnête et instructif : plus de la moitié du gain vient simplement du changement de modèle de base (BGE → e5), avant tout fine-tune. Le fine-tuning ajoute la couche de spécialisation par-dessus.
Note sur les baselines. Le seuil historique documenté dans la doctrine Nika est un MRR de 0,674 pour BGE-small. La valeur de 0,745 ci-dessus est ce que BGE-small obtient sur le golden BCUB3 actuel (n=100), un jeu différent. On cite les deux pour rester transparent : le gain réel se lit toujours à jeu de test constant, colonne contre colonne.
La boucle récursive, cycle par cycle
La figure d’en-tête montre l’essentiel : sur trois cycles successifs, le MRR golden du candidat (0,9162 → 0,9231 → 0,9292) progresse mais reste sous l’incumbent v1 (0,9408) et sous le seuil de gate (0,9358). Verdicts réels :
| Cycle | Date | Epochs | Paires | MRR golden candidat | Verdict | Coût |
|---|---|---|---|---|---|---|
| CONTINUOUS-FT-2 | 25/05 | 1 | — | 0,9162 | REJECTED (golden saturé, 1 epoch < checkpoint mûr de 3 epochs) | 0,115 $ |
| CONTINUOUS-FT-3 | 26/05 | 3 | 10 144 (+1 325) | 0,9231 | ROLLBACK (paires conversationnelles hors-distribution du golden) | 0,313 $ |
| FT-DAILY | 28/05 | 3 | 11 058 | 0,9292 | GO golden, mais cutover en HITL | 0,310 $ |
| FT-DAILY | 29/05 | 3 | +0 nouvelle paire | parité incumbent | GO (Δ vs incumbent +0,002) | 0,345 $ |
Trois enseignements concrets :
- Le gate fait son travail. Au cycle FT-3, l’ajout de 1 325 paires conversationnelles live a fait baisser le MRR golden (0,9231 < l’incumbent 0,9408) : ces paires sont hors-distribution par rapport à la cible de retrieval documentaire. Le système a fait un rollback propre vers l’incumbent. Plus de données n’est pas toujours mieux.
- Pas de cutover automatique. Même au cycle FT-DAILY où le candidat bat enfin l’incumbent (+0,0008, marge décisive mais infime), la promotion en production reste HITL (human-in-the-loop) : l’humain valide. L’adaptateur actif en production reste
CONTINUOUS-FT-3. - Le coût est dérisoire — environ 0,30 $ par cycle sur A100 louée à l’heure. Le facteur limitant n’est pas le calcul, c’est la discipline d’évaluation.
Le paradoxe de Funès
« Funes el memorioso »
Dans la nouvelle de Borges, Ireneo Funes, après une chute de cheval, se souvient de tout : chaque feuille de chaque arbre qu’il a vue, chaque instant dans son moindre détail. Et pourtant, écrit Borges, « penser, c’est oublier des différences, c’est généraliser, abstraire ». Funès, incapable d’oublier, est incapable de penser. Sa mémoire parfaite est une prison.
Au niveau du modèle : l’oubli catastrophique
Le paradoxe de Funès a un équivalent technique exact : l’oubli catastrophique (catastrophic forgetting). Si l’on spécialise trop violemment un modèle sur un corpus singulier — votre corpus —, il oublie les compétences généralistes acquises au pré-entraînement. Inversement, un modèle qui voudrait tout retenir sans rien abstraire ne généraliserait jamais. La compression et l’oubli sélectif sont la condition de l’intelligence, pour un agent comme pour Funès.
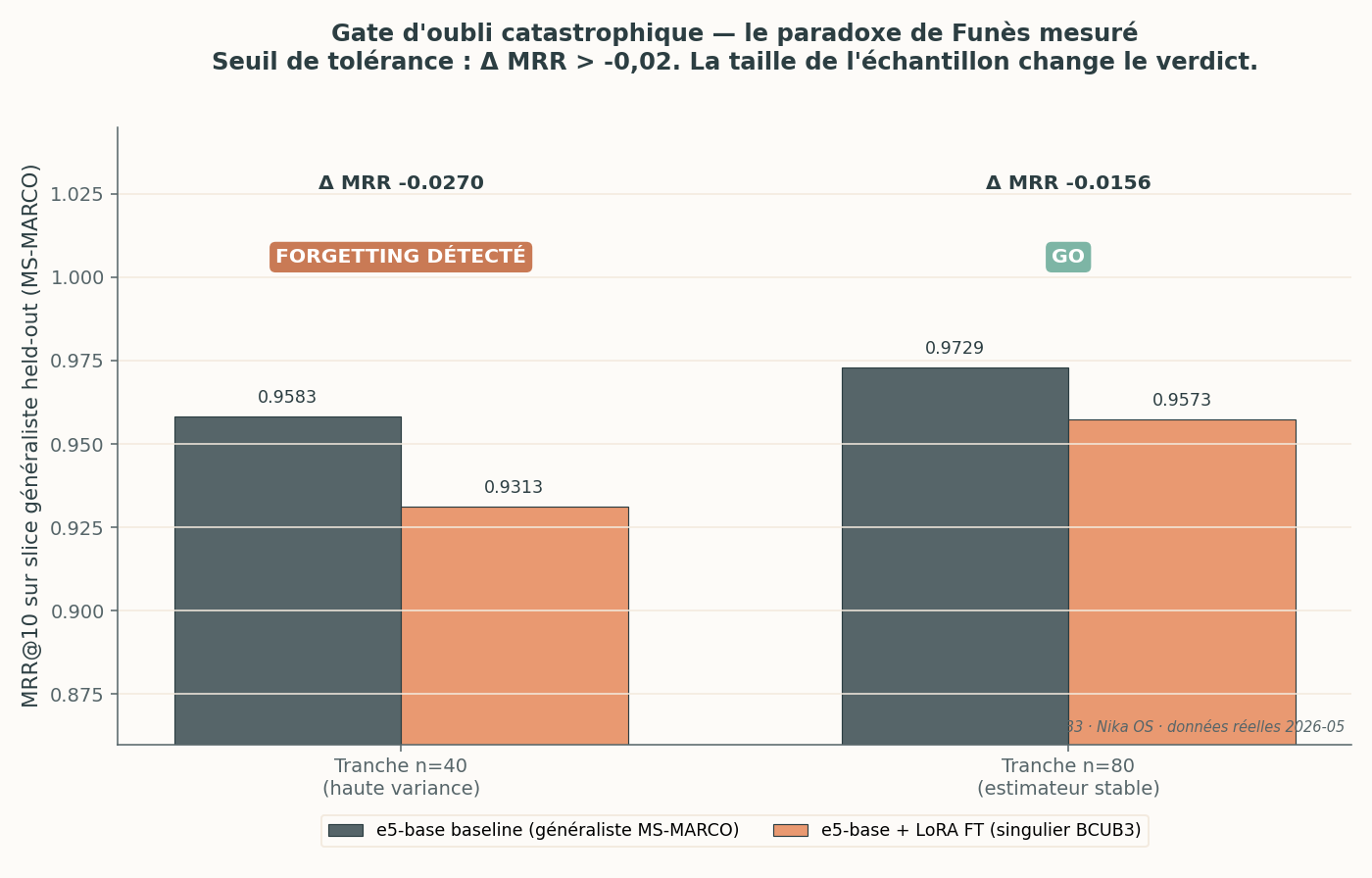 La même mesure d’oubli, sur deux tailles d’échantillon. À n=40, l’écart de −0,027 dépasse le seuil de tolérance (−0,02) et déclenche une alerte. À n=80, l’écart tombe à −0,016 : GO. La variance, pas l’oubli, expliquait l’alerte.
La même mesure d’oubli, sur deux tailles d’échantillon. À n=40, l’écart de −0,027 dépasse le seuil de tolérance (−0,02) et déclenche une alerte. À n=80, l’écart tombe à −0,016 : GO. La variance, pas l’oubli, expliquait l’alerte.
C’est ici que la pédagogie « effect size vs échantillon » devient concrète. Au cycle FT-DAILY, le gate d’oubli a tourné deux fois :
- Tranche n=40 : MRR généraliste baseline 0,9583 → fine-tuné 0,9313, soit Δ = −0,027. Le seuil de tolérance étant de −0,02, verdict : FORGETTING_DETECTED.
- Tranche n=80 (relance, échantillon doublé) : baseline 0,9729 → fine-tuné 0,9573, soit Δ = −0,016. Verdict : GO.
Le signal d’alerte initial venait de la variance d’un trop petit échantillon, pas d’un véritable oubli. Sur 40 questions où Recall@5 et Recall@10 valent déjà 1,0 pour les deux modèles, le MRR est extrêmement sensible à quelques inversions de rang. C’est exactement pourquoi on ne décide pas sur un n minuscule.
Les trois garde-fous obligatoires
Le fine-tuning récursif n’est défendable que parce qu’il embarque trois protections cumulables contre Funès :
- Rehearsal / replay. À chaque mini-batch, on ré-injecte des échantillons du corpus généraliste d’origine (MS-MARCO, MIRACL, BEIR) mêlés aux données singulières BCUB3, avec un coefficient de mélange. Le modèle ne dérive pas vers le seul corpus récent.
- Évaluation généraliste held-out permanente. En plus du golden BCUB3, on garde une tranche généraliste jamais vue à l’entraînement. Si son MRR chute de plus de 2 points → rollback. C’est précisément le gate de la figure ci-dessus.
- Checkpoint pré-FT + rollback automatique. Avant chaque cycle, on sauvegarde l’état du modèle. Si l’évaluation régresse, on revient à l’incumbent sans débat. Les verdicts
REJECTEDetROLLBACKdu tableau plus haut sont ce mécanisme en action.
Sans ces trois garde-fous, on reproduit l’erreur de Funès : tout mémoriser du présent, tout oublier du passé.
Le cadre honnête des risques
Risque α : « ça semble meilleur » sans chiffres
Le risque α (faux positif) est d’agir quand on n’aurait pas dû — promouvoir un modèle qui semble meilleur mais ne l’est pas. La parade est une règle dure : aucun changement ne part en production sur une impression. Il faut un gain mesuré, sur un jeu de test tenu à l’écart, supérieur à l’incumbent.
L’exemple canonique chez Nika est documenté : une tentative d’amélioration du retrieval par un boost de score post-hoc (re-pondération des résultats après coup, inspirée d’un cadre probabiliste Kelly-Taguchi-Weibull) a fait régresser le MRR de 0,674 à 0,358 — près de moitié. L’idée était séduisante sur le papier ; la mesure l’a tuée. Depuis, toute re-pondération de score post-hoc passe par un gate empirique obligatoire avant intégration. Ce qui marche en production, c’est l’inverse : intégrer la logique probabiliste dans le modèle (au niveau de l’activation et des hyperparamètres tunables), jamais en bonus de score après coup.
La leçon MiniLM : petit dataset, fine-tune contre-productif
Une expérience antérieure (18 mai) le confirme par l’absurde. Un fine-tune de all-MiniLM-L6-v2 sur 50 paires seulement, 1 epoch, a dégradé le modèle : Recall@1 de 0,227 à 0,182 (−0,045), Recall@3 de 0,455 à 0,318 (−0,136). Trop peu de données, et le fine-tune nuit. C’est ce qui justifie l’échelle des cycles actuels (11 000+ paires, 3 epochs) et le passage sur GPU.
Les limites de cette étude (dites explicitement)
- Le golden set sature. À n=100 avec des questions en partie synthétiques, Recall@5 et Recall@10 atteignent 1,0 : seul le MRR (et le Recall@1) restent discriminants. Un golden plus large et plus difficile, bâti sur les vraies requêtes, est la prochaine étape.
- Les tranches d’oubli sont petites (n=40, n=80). On l’a vu : le verdict bascule avec la taille. Les estimations stables exigent une tranche plus grande, ce que le cron utilise désormais.
- La couverture du corpus re-embeddé est partielle. Lors de la migration test vers la collection 768d, seuls 619 points sur 355 777 ont été ré-embeddés (0,2 %) — le reste (e-mails, factures, documents moissonnés) vit dans des pipelines non rejoués pour ce test. Conséquence : sur l’évaluation agrégée toutes requêtes, le Recall@10 baisse de −0,02 — non pas parce que le modèle est moins bon, mais parce que le contenu cherché n’était pas encore ré-ingéré. Sur les sondes spécifiquement BCUB3/Nika, en revanche, le nouveau modèle gagne 3 cas sur 5, parfois massivement. C’est un écart de couverture, pas une régression de modèle — et le distinguer honnêtement est tout l’objet d’un cadre de risque sérieux.
FAQ
Qu’est-ce que le fine-tuning récursif des embeddings ?
C’est le ré-entraînement périodique et automatisé du modèle qui transforme les textes en vecteurs, sur les nouvelles données d’un corpus, avec une règle stricte : une nouvelle version n’est promue en production que si elle bat l’ancienne sur un jeu de test tenu à l’écart (held-out). Chaque cycle enchaîne entraînement LoRA, évaluation golden, contrôle d’oubli généraliste, puis promotion (cutover) ou retour arrière (rollback).
Quelle est la différence entre Recall@k, MRR et nDCG ?
Le Recall@k mesure si le bon document est ramené dans les k premiers résultats (couverture). Le MRR récompense le fait de le classer haut (1/rang du premier bon résultat). Le nDCG affine encore en pénalisant logarithmiquement les bonnes réponses placées en bas et en tenant compte d’une pertinence graduée. Pour un RAG, le MRR est l’indicateur le plus important car le LLM lit surtout les premiers passages.
Qu’est-ce que l’oubli catastrophique en fine-tuning ?
C’est la perte des compétences généralistes d’un modèle quand on le spécialise trop sur un corpus singulier. C’est le paradoxe de Funès appliqué au modèle : tout retenir du présent fait oublier le passé. On le mesure en évaluant le modèle fine-tuné sur une tranche généraliste jamais vue à l’entraînement ; si son score chute au-delà d’un seuil, on refuse la promotion.
Comment se protéger de l’oubli catastrophique ?
Trois techniques cumulables : (1) le rehearsal/replay — ré-injecter à l’entraînement des échantillons du corpus généraliste d’origine ; (2) une évaluation généraliste held-out permanente qui sert de garde-fou ; (3) un checkpoint pré-entraînement avec rollback automatique si l’évaluation régresse. Garder le backbone gelé via LoRA est une quatrième protection, par construction.
Pourquoi un gain mesuré sur 40 questions n’est-il pas fiable ?
Parce que la variance d’un petit échantillon domine le signal. Dans un cas réel mesuré chez Nika, un écart de MRR de −0,027 sur 40 questions (au-delà du seuil d’alerte) est tombé à −0,016 — sous le seuil — dès qu’on est passé à 80 questions. La taille d’effet doit toujours être lue avec la taille de l’échantillon : un écart sur trop peu de cas n’est pas une preuve.
Le fine-tuning améliore-t-il toujours le modèle ?
Non. Sur un dataset trop petit (50 paires, un cas mesuré), le fine-tune a dégradé le Recall@1 de −0,045. Et ajouter des données hors-distribution (paires conversationnelles sur une cible de retrieval documentaire) a fait baisser le MRR golden et déclenché un rollback. Plus de données ou plus d’entraînement ne valent que s’ils sont évalués — c’est tout l’objet du gate empirique.
Pour aller plus loin
Cet article fait partie de notre socle technique sur le RAG et l’IA appliquée. Les termes en gras renvoient au glossaire technique BCUB3. Articles liés :
- Similarité cosinus, euclidienne, dot, Jaccard : choisir sa métrique RAG
- Stack IA open-source en entreprise : 7 briques + Mem Palace
- Mode opératoire : entraîner un SLM industriel de A à Z
- SEO & GEO technique 2026 : données structurées pour les LLM
Méthodologie : toutes les courbes de cet article proviennent des journaux d’entraînement et d’évaluation réels de la boucle de fine-tuning récursif de Nika OS (cycles CONTINUOUS-FT-2/3 et FT-DAILY, 25–29 mai 2026), sur GPU NVIDIA A100. Seed déterministe 42. Aucune valeur de courbe n’a été reconstituée ; les données manquantes sont signalées comme limites.